栈溢出漏洞原理
1 缓冲区溢出简介(堆、栈溢出)
经常听到什么栈溢出,堆溢出,其实他们都属于缓冲区溢出。
根据维基百科的解释:
缓冲区溢出(buffer overflow),
在计算机科学上是指针对程序设计缺陷,向程序输入缓冲区写入使之溢出的内容(通常是超过缓冲区能保存的最大数据量的数据),从而破坏程序运行、趁着中断之际并获取程序乃至系统的控制权。
缓冲区溢出原指当某个数据超过了处理程序回传堆栈地址限制的范围时,程序出现的异常操作。
对于初学者,要完全理解这段解释,还需要对寄存器,内存,缓冲区,代码执行机制有一定的了解。
下面我就尝试以一个通俗易懂的角度解释上述内容。
.
.
2 内存
一段代码被执行的时候,一定会使用到内存来存放数据。
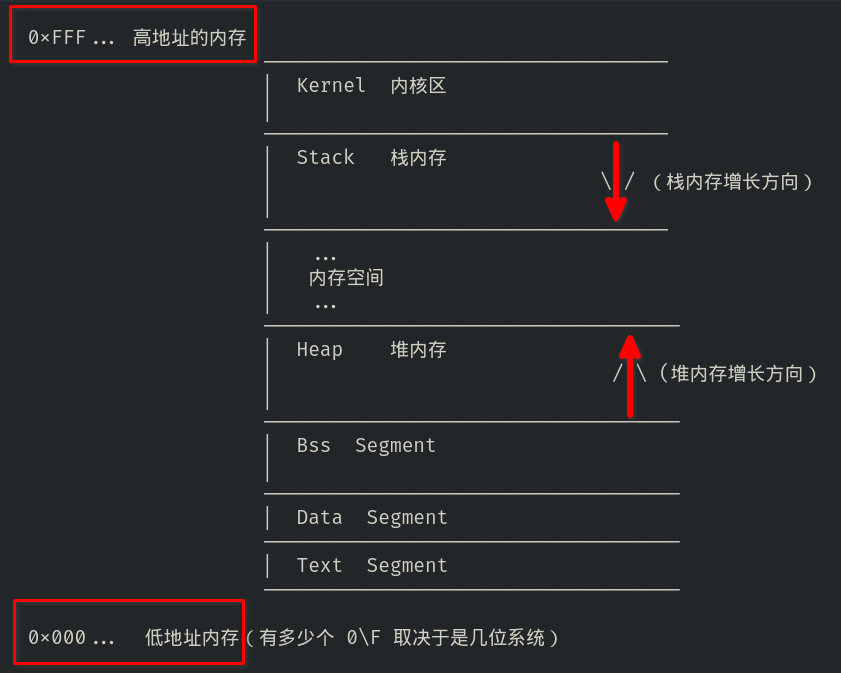
拿 C 语言来举例,对于一个普通的 C 语言程序, 它的内存由 5 个部分(Segment)组成, 每一个部分都有不同的用途。
为了更加完整一点,我又多画了一个 Kernel 内核区
如下图:
.
每个部分的解释:
Text 代码区:
- 存放程序的可执行代码。这一内存块通常是只读的。
Data 数据区:
- 存放已经初始化值了的静态变量和全局变量
Bss 区:
- 存放未被初始化值的静态变量和全局变量。系统会把这部分存放的值都用 0 来储存。
Heap 堆内存:
- 用于动态分配内存分配,在 C 语言中,堆内存由 malloc()、calloc()、realloc()、free() 管理。意思就是使用这些函数的地方,其数据都会被保存在堆内存
- 如果是有引用类型的变量,总是会放在堆内存中的
- 还有一点值得注意的,堆内存的增长方向和内存地址增长方向是一样的
Stack 栈内存:
存放函数内定义的局部变量,以及和函数调用相关的数据(实参,函数返回地址)
关键点:
栈内存的增长方向和内存地址的增长方向正相反,这么设计的原因是,假如栈内存的增长方向和内存地址的增长方向一样,那么假如栈内存的栈顶在内存地址的较高地址处,随着栈内存的增长,很容易就会造成内存溢出。而如果像现在这样,栈内存和内存地址的增长方向相对,那么就可以一定程度上避免内存溢出。
Kernel 内核区:
- 主要用来存放从命令行调用程序时传入的参数,以及某些环境变量
.
.
3 栈内存
那么经过上图的理解,对缓冲区溢出有了进一步的认识了吧。可以简单地理解缓冲区就是内存里放数据的地方,然后缓冲区包括栈内存和堆内存,当栈内存或者堆内存储存的数据过大,超越了边界,就造成了缓冲区溢出。
虽然缓冲区溢出分为堆溢出和栈溢出,但在此篇文章我们重点讲解 栈溢出
要讲清楚栈溢出,首先更加了解栈内存结构
如下图:
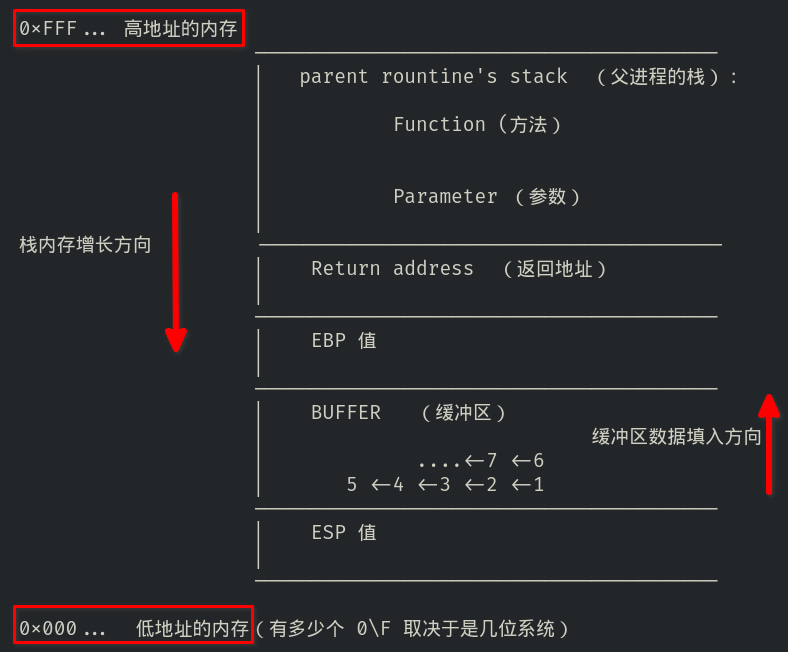
.
这是一段有栈内存空间存储数据的代码的栈内存结构图
对于其中的内容我们一一解释:
首先是最上面的 Parent rountine ‘ s stack ,即父进程(线程)的栈。它保存着上一个被调用的函数的数据,最基础的比如 Function (方法),Parameters (参数)。
然后是 Return address ,即返回地址。要知道每个函数被调用之后,执行完功能,都必须返回(无论有没有返回值)。那么返回到什么地方,就由这个 返回地址 来标明。
接下来是 EBP 值,实际上 EBP 是寄存器存放当前线程的栈底指针。而在栈内存中,EBP 值就是一段地址数据,会被 寄存器 EBP 记录,所以直接就叫做 EBP 值。
从这里开始,就可以算作是新栈(子线程或者新函数)的开始点了
Buffer 缓冲区,这里直接放个缓冲区其实是有点突兀的。因为我没有在前面写清楚代码,所以在这补充一下:之所以这里有一个 Buffer 缓冲区,是因为我为了说明缓冲区溢出,假定了代码中有一个使用到缓冲区的部分,所以才会在这里出现缓冲区 Buffer。
此外,还需要注意一点的是,缓冲区中数据流入的方向和内存地址增长方向相同。如上图所标
最后是 ESP 值,原本也是指寄存器的一种。ESP 寄存器存放当前线程的栈顶指针,在栈内存这里就表示栈顶的值。栈顶部是内存地址较小的区域,圧入栈的数据越多,ESP值也就越来越小
补充:
- 说到寄存器,就要稍微提一下那几个 E 开头的东西(ESP,EBP,EIP)。首先要知道 E 开头表示是 32 位系统的寄存器,64 位的寄存器是 R 开头的
- 前面讲了 EBP,ESP。还有一个比较关键的寄存器 EIP 没介绍:
- EIP:寄存器存放下一个CPU指令存放的内存地址,当CPU执行完当前的指令后,从EIP寄存 器中读取下一条指令的内存地址,然后继续执行。
.
.
4 栈溢出漏洞原理
结合前面缓冲区溢出的概念,以及栈内存结构,那么栈溢出漏洞的原理也不难。
首先要制造溢出,在栈内存结构图中我说明了 Buffer 缓冲区的数据增长方向,是和内存地址增长方向相同的。也就是随着数据的增长,会慢慢溢出,覆盖 EBP 值,然后覆盖到 Return Address 返回地址。而覆盖返回地址,并将其中的值填充成我们要的目标地址的值。
这么做的原因是,前面我们说过当函数执行完毕后,会根据 Return Address 中的返回地址值返回到某个特定的位置,然后再从那个位置继续执行代码。那么如果这个地址可以被我们自由操作,只需要将其改成我们 shellcode 的地址值,不就任意代码执行了吗?
.
那么这个 shellcode 的地址值要怎么写?或者说要怎么才能准确的知道 shellcode 的内存地址值?
甚至说 shellcode 要怎么写?写在哪?
.
解答:
shellcode 要写在哪?怎么写?
由于我们从一开始就只能控制写入缓冲区中的数据,因此 shellcode 一定是写在缓冲区中的,而且一定是在 目标返回地址 的前面。总的来说,shellcode 应该是写在我们填入缓冲区数据的中间那部分。
还有一点就是 shellcode 的形式是 16 进制的机械码,这段机械码是可以被 CPU 读懂的并且能够执行指令的。
通俗来讲就是一串16进制的机器码,由CPU解释为操作指令 ,最后由内存加载执行。这些操作指令可以由工具生成,也可以自己编写,但通常我们都借助 msf 之类工具来编写。
Return Address 那里要填入的 shellcode 的地址值要怎么写?
上面说到 shellcode 是写在填入缓冲区数据的中间部分,其实可以通过一些工具查看寄存器中保存的地址来准确找到 shellcode 的地址
但要每次都准确找到就有点麻烦,所以这里有个技巧。可以在填入的缓冲区数据的前半部分(在 shellcode 之前),加入 \x90 这个机器码,它的意思是继续前进去读取下一个内存地址里的数据。
那么在前半部分加入了 \x90 之后,即使我们在 Return Address 部分填入 shellcode 的地址没有那么准确,也没有关系,毕竟只要落到了 \x90 这段数据中,就必然会执行到 shellcode 的位置。
可以理解为下图:

(红色部分是 Return Address ,被遮挡住)
那么到此为止,栈溢出漏洞的原理我们已经了解了大概了,总结起来就是通过向栈中缓冲区填入有针对性修改的数据,这些数据包括 /x90 (前半部分),shellcode (中间部分),以及最后要覆盖到 Return Address 的 shellcode 的大概范围的内存地址值(后半部分)。从而实现任意命令(代码)执行,完成攻击。
.
.
/